
Unsupervised visual odometry method for greenhouse mobile robots
-
摘要:
针对温室移动机器人自主作业过程中,对视觉里程信息的实际需求及视觉里程估计因缺少几何约束而易产生尺度不确定问题,提出一种基于无监督光流的视觉里程估计方法。根据双目视频局部图像的几何关系,构建了局部几何一致性约束及相应光流模型,优化调整了光流估计网络结构;在网络训练中,采用金字塔层间知识自蒸馏损失,解决层级光流场缺少监督信号的问题;以轮式移动机器人为试验平台,在种植番茄温室场景中开展相关试验。结果表明,与不采用局部几何一致性约束相比,采用该约束后,模型的帧间及双目图像间光流端点误差分别降低8.89%和8.96%;与不采用层间知识自蒸馏相比,采用该处理后,两误差则分别降低11.76%和11.45%;与基于现有光流模型的视觉里程估计相比,该方法在位姿跟踪中的相对位移误差降低了9.80%;与多网络联合训练的位姿估计方法相比,该误差降低了43.21%;该方法可获得场景稠密深度,深度估计相对误差为5.28%,在1 m范围内的位移平均绝对误差为3.6 cm,姿态平均绝对误差为1.3º,与现有基准方法相比,该方法提高了视觉里程估计精度。研究结果可为温室移动机器人视觉系统设计提供技术参考。
Abstract:Simultaneous Localization and Mapping (SLAM) is one of the most crucial aspects of autonomous navigation in mobile robots. The core components of the SLAM system can be depth perception and pose tracking. However, the existing unsupervised learning visual odometry framework cannot fully meet the actual requirements of the visual odometry information, particularly on the scale uncertainty in visual odometry estimation. It is still lacking in the geometric constraints during the autonomous operation of greenhouse mobile robots. In this study, an unsupervised optical flow-based visual odometry was presented. An optical flow estimation network was trained in an unsupervised manner using image warping. The optical flow between stereo images (disparity) was used to calculate the absolute depth of scenes. The optical flow between adjacent frames of left images was combined with the scene depth, in order to solve the frame-to-frame pose transformation matrix using Perspective-n-Point (PnP) algorithm. The reliable correspondences were selected in the solving process using forward and backward flow consistency checking to recover the absolute pose. A compact deep neural network was built with the convolutional modules to serve as the backbone of the flow model. This improved network was designed, according to the well-established principles: pyramidal processing, warping, and the use of a cost volume. At the same time, the cost volume normalization in the network was estimated with high values to alleviate the feature activations at higher levels than before. Furthermore, the local geometric consistency constraints were designed for the objective function of flow models. Meanwhile, a pyramid distilling loss was introduced to provide the supervision for the intermediate optical flows via distilling the finest final flow field as pseudo labels. A series of experiments were conducted using a wheeled mobile robot in a tomato greenhouse. The results showed that the better performance was achieved in the improved model. The local geometric consistency constraints improved the optical flow estimation accuracy. The endpoint error (EPE) of inter-frame and stereo optical flow was reduced by 8.89% and 8.96%, respectively. The pyramid distillation loss significantly reduced the optical flow estimation error of the flow model, in which the EPEs of the inter-frame and stereo optical flow decreased by 11.76% and 11.45%, respectively. The EPEs of the inter-frame and stereo optical flow were reduced by 12.50% and 7.25%, respectively, after cost volume normalization. Particularly, the price decreased by 1.28% for the calculation speed of the optical flow network. This improved model showed a 9.52% and 9.80% decrease in the root mean square error (RMSE) and mean absolute error (MAE) of relative translation error (RTE), respectively, compared with an existing unsupervised flow model. The decrease was 43.0% and 43.21%, respectively, compared with the Monodepth2. The pose tracking accuracy of this improved model was lower than that of ORB-SLAM3. The pure multi-view geometry shared the predicting dense depth maps of a scene. The relative error of depth estimation was 5.28% higher accuracy than the existing state-of-the-art self-supervised joint depth-pose learning. The accuracy of pose tracking depended mainly on the motion speed of robots. The performance of pose tracking at 0.2 m/s low speed and 0.8 m/s fast speed was significantly lower than that at 0.4-0.6 m/s. The resolution of the input image greatly impacted the pose tracking accuracy, with the errors decreasing gradually as the resolution increased. The MAE of RTE was not higher than 3.6 cm with the input image resolution of 832×512 pixels and the motion scope of 1 m, whereas, the MAE of relative rotation error (RRE) was not higher than 1.3º. These findings can provide technical support to design the vision system of greenhouse mobile robots.
-
Keywords:
- robot /
- greenhouse /
- navigation /
- visual odometry /
- unsupervised learning /
- optical flow /
- convolutional neural network
-
-
![]()
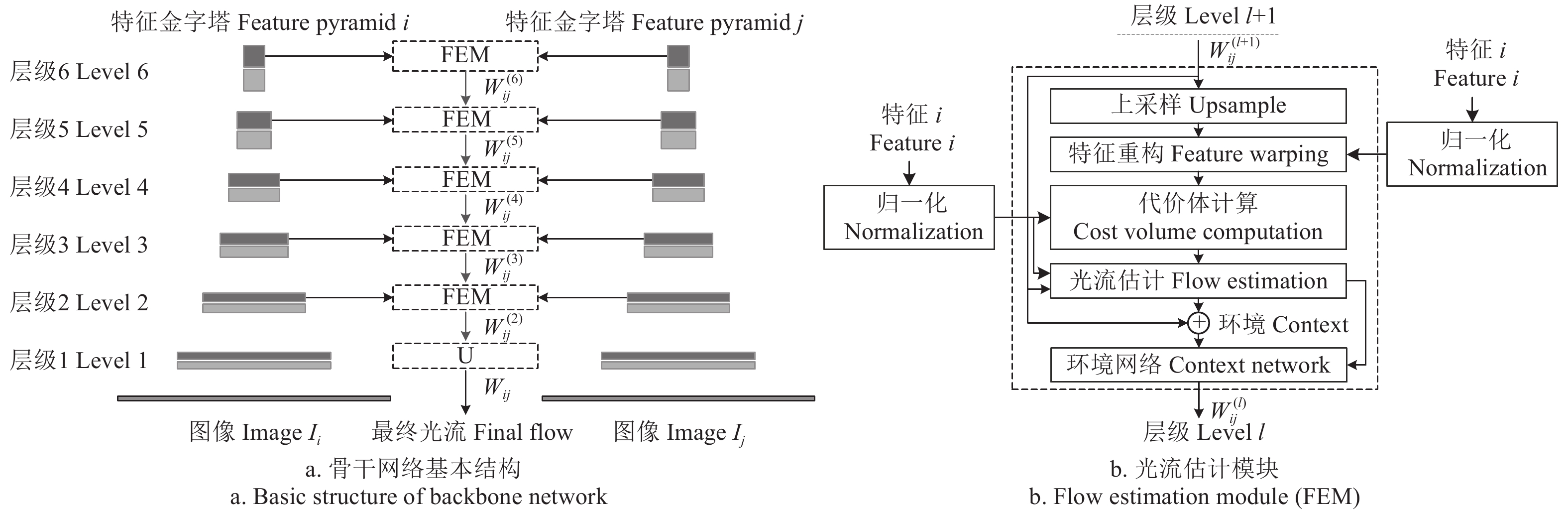
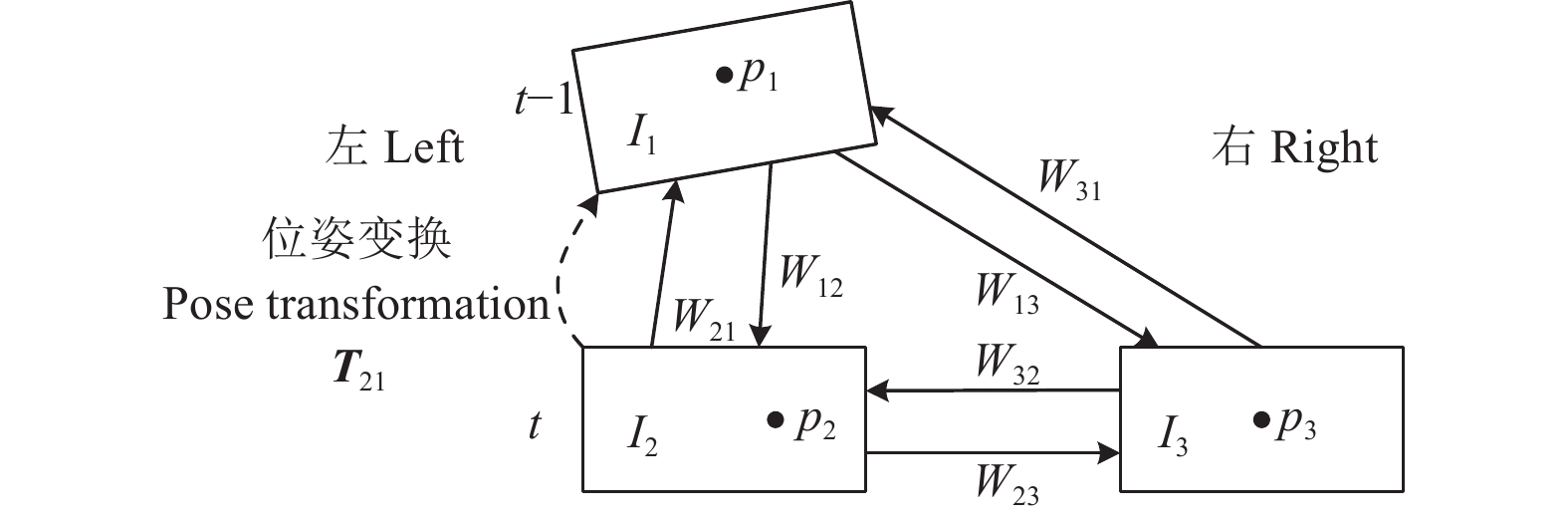
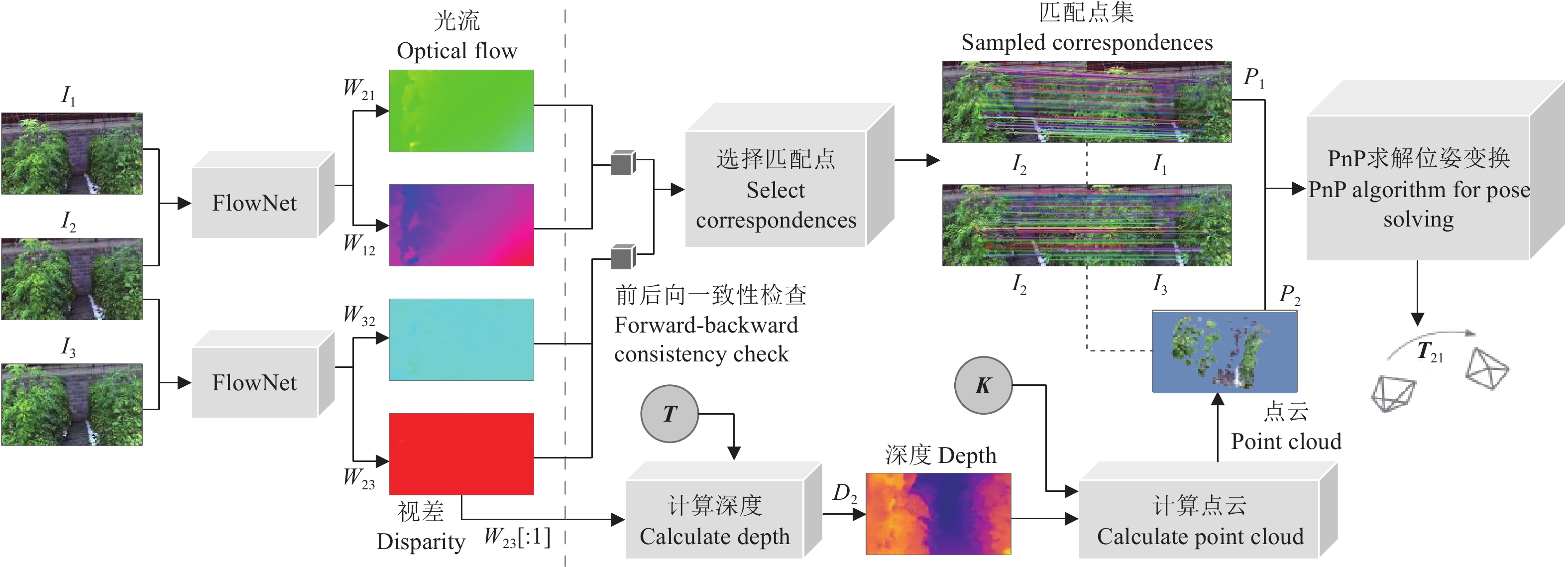
图 1 基于光流的视觉里程估计框架图
注:I1为t-1时刻的左目图像;I2、I3分别表示t时刻的左、右目图像;FlowNet表示光流估计网络;Wij为Ii到Ij的光流场,i, j∈{1, 2, 3};W23[:1]表示t时刻双目图像间视差;D2为深度图;K、T分别表示相机内、外参矩阵;p1表示图像I1上的二维坐标点;P2表示三维坐标点;T21表示帧间位姿变换矩阵。下同。
Figure 1. Framework diagram of visual odometer based on optical flow
Note: I1 represents the left image at time t-1; I2 and I3 correspond to the left and right images from a calibrated stereo pair captured at time t; FlowNet represents optical flow estimation network; Wij is the optical flow fields from Ii to Ij, i, j∈{1, 2, 3}; W23[:1] represents the disparity between binocular images at time t; D2 is the depth map; K and T represent intrinsic and extrinsic of stereo camera; p1 means coordinate point in I1; P2 represents a 3D coordinate point; T21 denotes the inter-frame pose transformation matrix. The same below.
![]()
图 2 深度神经网络结构
注:U表示上采样模块;W(l)ij表示层级光流场,l∈{2, 3, 4, 5, 6}。
Figure 2. The structure of deep neural network
Note: U represents upsampling module; W(l)ijdenotes the hierarchical optical flow field, l∈{2, 3, 4, 5, 6}.
![]()
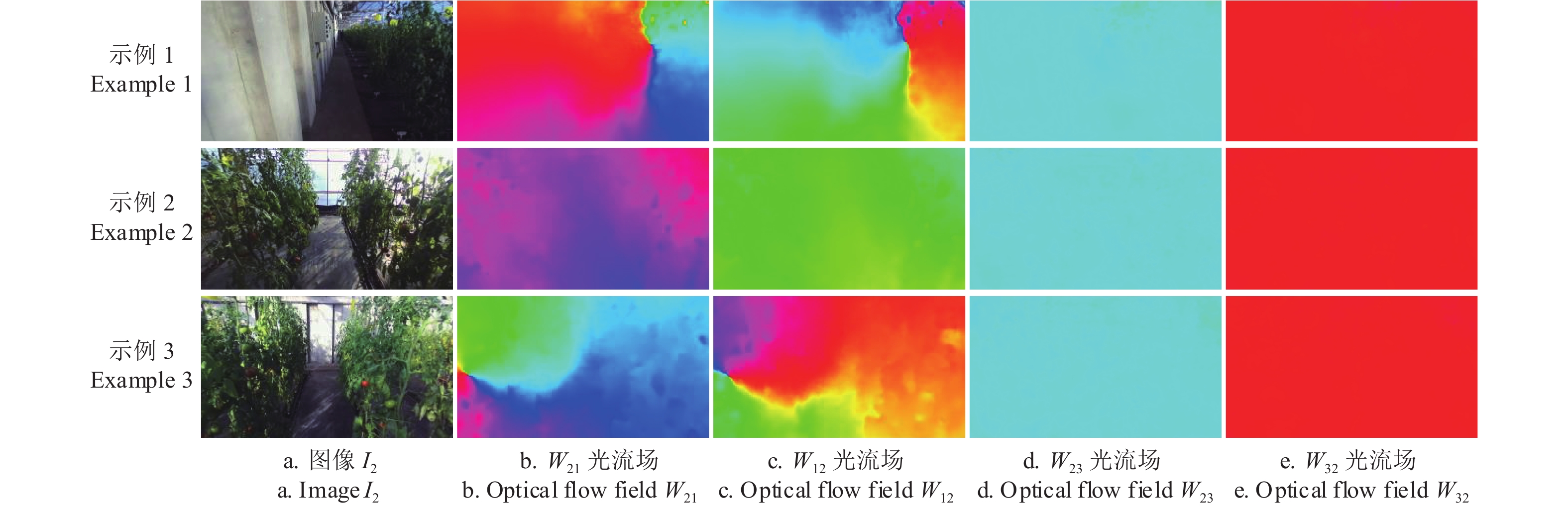
图 5 局部光流场示例
注:光流场图的不同颜色表示光流向量方向差异,不同亮度表示向量大小差异。
Figure 5. Examples of local optical flow field
Note: The different colors of the optical flow map represent differences in the flow direction, and different brightness represents differences in the flow size.
![]()
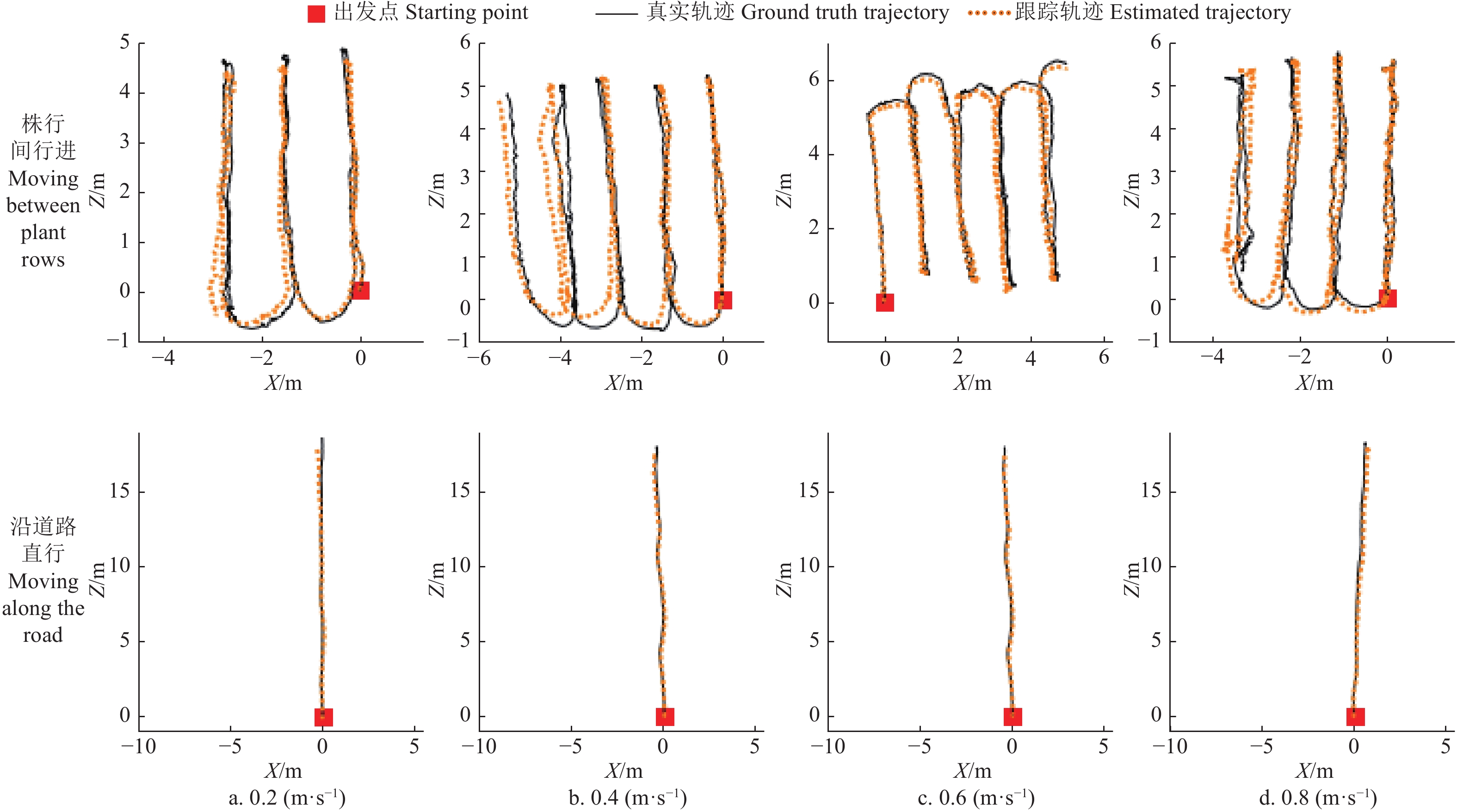
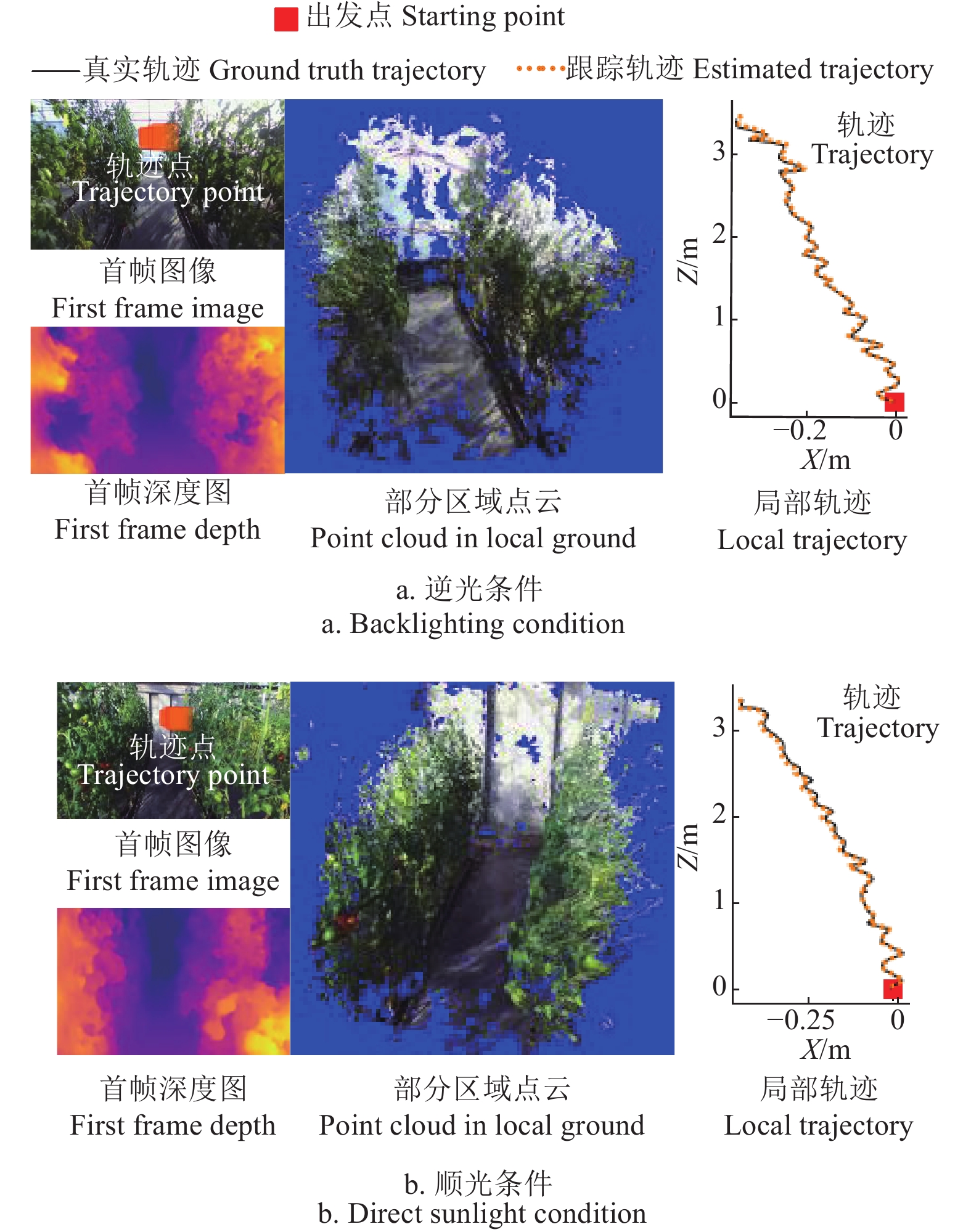
图 6 不同行进速度下的轨迹跟踪示例
注:Z表示机器人在出发点位置时的前视方向,X表示垂直于Z的水平方向。下同。
Figure 6. Examples of trajectory tracking at different motion speed
Note: Z represents the forward looking direction of the robot at the starting point position, and X represents the horizontal direction perpendicular to Z. The same below.
表 1 不同网络损失模型的无监督光流估计精度
Table 1 Unsupervised optical flow estimation accuracy for different network loss models
模型名称
Model name模型损失项的线性组合系数设置
Settings of linear combination coefficient for model loss termI2⇌I1 I2⇌I3 I1⇌I2⇌I3⇌I1 λc λt λd λe λu EPE F1/% EPE F1/% EPE F1/% I 0 0 0 0 0 0.52±0.00 a 0.74±0.00 a 2.26±0.01 a 10.35±0.09 a 2.76±0.02 a 7.89±0.05 a II 1.0 0 0 0 0 0.51±0.00 b 0.70±0.00 b 2.27±0.02 a 10.01±0.03 b 2.70±0.01 b 7.87±0.01 a III 1.0 0.01 0 0 0 0.45±0.00 c 0.54±0.00 c 2.01±0.01 b 8.25±0.01 c 2.58±0.02 c 6.50±0.02 b IV 1.0 0.01 0.1 0 0 0.43±0.00 d 0.53±0.00 d 1.93±0.01 c 7.63±0.03 d 2.44±0.02 d 6.26±0.01 c V 1.0 0.01 0.1 0.01 0 0.42±0.00 d 0.51±0.00 e 1.90±0.01 c 7.52±0.02 d 2.43±0.01 d 6.05±0.01 d VI 1.0 0.01 0.1 0.01 0.01 0.41±0.00 e 0.47±0.01 f 1.83±0.01 d 7.02±0.03 e 2.29±0.02 e 5.82±0.01 e 注:模型I、II、III、IV、V、VI的骨干网络相同,结构如图2所示;λc、λt 、λd 、λe 、λu 为式(10)中的线性组合系数,系数为0表示在损失函数中不使用对应损失项;⇌表示双向光流;EPE表示端点误差;F1表示错误率;数据为平均值±标准误差;不同小写字符表示各模型在5%水平上差异显著。下同。 Note: The backbone network of models I, II, III, IV, V and VI are same, and the structure is shown in Figure 2; λc, λt , λd , λe , λu correspond to the linear combination coefficient in equation (10), coefficient of 0 means that the corresponding loss term is not used;⇌ represents the bidirectional optical flow; EPE means endpoint error; F1 represents the percentage of erroneous pixels; Data is mean±SE; Values followed by a different letter within a column for models are significantly different at the 0.05 level. The same below.  下载: 导出CSV
下载: 导出CSV
表 2 不同网络结构的无监督光流估计精度
Table 2 Unsupervised optical flow estimation accuracy for different network structures
网络
NetworksI2⇌I1 I2⇌I3 I1⇌I2⇌I3⇌I1 计算速度
Computation speed/(帧·s−1)EPE F1/% EPE F1/% EPE F1/% PWC-Net 0.48±0.00 a 0.61±0.01 a 2.07±0.01 a 8.72±0.04 a 2.65±0.02 a 7.11±0.02 a 19.56±0.03 a Φ0 0.42±0.00 b 0.53±0.00 b 1.92±0.01 b 7.73±0.02 b 2.44±0.02 b 6.30±0.04 b 19.31±0.05 b Φ 0.41±0.00 c 0.47±0.00 c 1.83±0.01 c 7.02±0.03 c 2.29±0.02 c 5.82±0.01 c 16.56±0.02 c
下载: 导出CSV
表 3 不同方法的位姿跟踪性能比较
Table 3 Accuracy comparison of different methods on pose tracking
方法
MethodsRTE/m RRE/rad ATE/m RMSE MAE RMSE MAE RMSE MAE UpFlow[29] 0.063±0.002 b 0.051±0.002 b 0.033±0.001 b 0.029±0.001 b 0.489±0.006 b 0.393±0.004 b Monodepth2[19] 0.100±0.001 a 0.081±0.001 a 0.044±0.000 a 0.037±0.001 a 0.625±0.003 a 0.490±0.005 a ORB-SLAM3[8] 0.039±0.000 d 0.034±0.000 d 0.011±0.000 d 0.010±0.000 d 0.274±0.000 d 0.216±0.000 d 本文方法 Proposed method 0.057±0.002 c 0.046±0.001 c 0.032±0.000 c 0.027±0.000 c 0.470±0.003 c 0.379±0.003 c 注:RTE、RRE和ATE分别表示相对位移误差、相对姿态误差和绝对轨迹误差;RMSE和MAE分别表示均方根误差和平均绝对误差。下同。 Note: RTE, RRE and ATE represent relative translation error, relative rotation error and absolute trajectory error respectively; RMSE means root mean square error, MAE is short for mean absolute error. The same below.
下载: 导出CSV
表 4 不同方法的深度估计性能比较
Table 4 Accuracy comparison of different methods on depth estimation
方法
Methods深度估计误差 Depth estimation error 阈值限定精度 Accuracy with threshold/% Rel/% Sq Rel RMSE/m RMSElg δ<1.25 δ<1.252 δ<1.253 UpFlow[29] 6.27±0.12 b 0.038±0.001 b 0.401±0.010 b 0.115±0.002 b 89.63±0.30 a 93.50±0.18 c 95.42±0.13 b Monodepth2[19] 8.18±0.14 a 0.066±0.000 a 0.532±0.016 a 0.135±0.002 a 86.23±0.24 b 93.96±0.09 b 96.07±0.08 a 本文方法 Proposed method 5.28±0.06 c 0.032±0.001 c 0.379±0.003 b 0.104±0.001 c 91.00±0.25 a 94.05±0.18 a 95.60±0.13 b 注:Rel、Sq Rel和RMSElg分别表示平均相对误差、平方相对误差和lg化RMSE。δ的含义同式(11)。 Note: Rel means mean relative error; Sq Rel stands for squared relative error; RMSElg means lg RMSE. δ has the same meaning as equation (11).
下载: 导出CSV
表 5 不同运动速度下的位姿跟踪性能
Table 5 Pose tracking performance under different motion speeds
运动速度
Motion speed/(m·s−1)RTE/m RRE/rad ATE/m RMSE MAE RMSE MAE RMSE MAE 0.2 0.047±0.001 b 0.042±0.001 b 0.031±0.000 b 0.027±0.001 b 0.474±0.010 b 0.386±0.002 b 0.4 0.043±0.003 b 0.042±0.001 b 0.025±0.000 c 0.021±0.000 c 0.461±0.000 b 0.330±0.007 c 0.6 0.037±0.001 c 0.036±0.001 c 0.023±0.000 d 0.021±0.001 c 0.311±0.007 c 0.264±0.002 d 0.8 0.108±0.002 a 0.067±0.003 a 0.044±0.001 a 0.036±0.001 a 0.662±0.014 a 0.512±0.004 a
下载: 导出CSV
表 6 不同输入图像分辨率的位姿跟踪性能
Table 6 Performance of pose tracking with different input image resolutions
分辨率
Resolution/像素RTE/m RRE/rad ATE/m RMSE MAE RMSE MAE RMSE MAE 448×256 0.065±0.001 a 0.054±0.000 a 0.036±0.000 a 0.031±0.000 a 0.706±0.005 a 0.553±0.004 a 512×320 0.057±0.002 b 0.046±0.001 b 0.032±0.000 b 0.027±0.000 b 0.470±0.003 b 0.379±0.003 b 768×448 0.054±0.000 b 0.040±0.000 c 0.031±0.000 c 0.026±0.000 c 0.351±0.003 c 0.284±0.001 c 832×512 0.049±0.001 c 0.036±0.002 d 0.027±0.001 d 0.023±0.000 d 0.343±0.003 c 0.279±0.002 c
下载: 导出CSV
-
[1] MIN H K, RYUH B S, KIM K C, et al. Autonomous greenhouse mobile robot driving strategies from system integration perspective:Review and application[J]. IEEE/ASME Transactions on Mechatronics, 2014, 20(4):1-12. MIN H K, RYUH B S, KIM K C, et al. Autonomous greenhouse mobile robot driving strategies from system integration perspective: Review and application[J]. IEEE/ASME Transactions on Mechatronics, 2014, 20(4): 1-12.
[2] 钟银,薛梦琦,袁洪良. 智能农机GNSS/INS组合导航系统设计[J]. 农业工程学报,2021,37(9):40-46. ZHONG Yin, XUE Mengqi, YUAN Hongliang. Design of the GNSS/INS integrated navigation system for intelligent agricultural machinery[J]. Transactions of the Chinese Society of Agricultural Engineering (Transactions of the CSAE), 2021, 37(9): 40-46. (in Chinese with English abstract ZHONG Yin, XUE Mengqi, YUAN Hongliang. Design of the GNSS/INS integrated navigation system for intelligent agricultural machinery[J]. Transactions of the Chinese Society of Agricultural Engineering (Transactions of the CSAE), 2021, 37(9): 40-46. (in Chinese with English abstract)
[3] 居锦,刘继展,李男,等. 基于侧向光电圆弧阵列的温室路沿检测与导航方法[J]. 农业工程学报,2017,33(18):180-187. JU Jin, LIU Jizhan, LI Nan, et al. Curb-following detection and navigation of greenhouse vehicle based on arc array of photoelectric switches[J]. Transactions of the Chinese Society of Agricultural Engineering (Transactions of the CSAE), 2017, 33(18): 180-187. (in Chinese with English abstract JU Jin, LIU Jizhan, LI Nan, et al. Curb-following detection and navigation of greenhouse vehicle based on arc array of photoelectric switches[J]. Transactions of the Chinese Society of Agricultural Engineering (Transactions of the CSAE), 2017, 33(18): 180-187. (in Chinese with English abstract)
[4] CHEN J Q, HU Q, WU J H, et al. Extracting the navigation path of a tomato-cucumber greenhouse robot based on a median point Hough transform[J]. Computers and Electronics in Agriculture, 2020, 174:105472. CHEN J Q, HU Q, WU J H, et al. Extracting the navigation path of a tomato-cucumber greenhouse robot based on a median point Hough transform[J]. Computers and Electronics in Agriculture, 2020, 174: 105472.
[5] 杨洋,马强龙,陈志桢,等. 激光雷达实时提取甘蔗垄间导航线[J]. 农业工程学报,2022,38(4):178-185. YANG Yang, MA Qianglong, CHEN Zhizhen, et al. Real-time extraction of the navigation lines between sugarcane ridges using LiDAR[J]. Transactions of the Chinese Society of Agricultural Engineering (Transactions of the CSAE), 2022, 38(4): 178-185. (in Chinese with English abstract YANG Yang, MA Qianglong, CHEN Zhizhen, et al. Real-time extraction of the navigation lines between sugarcane ridges using LiDAR[J]. Transactions of the Chinese Society of Agricultural Engineering (Transactions of the CSAE), 2022, 38(4): 178-185. (in Chinese with English abstract)
[6] 宫金良,孙科,张彦斐,等. 基于梯度下降和角点检测的玉米根茎定位导航线提取方法[J]. 农业工程学报,2022,38(13):177-183. GONG Jinliang, SUN Ke, ZHANG Yanfei, et al. Extracting navigation line for rhizome location using gradient descent and corner detection[J]. Transactions of the Chinese Society of Agricultural Engineering (Transactions of the CSAE), 2022, 38(13): 177-183. (in Chinese with English abstract GONG Jinliang, SUN Ke, ZHANG Yanfei, et al. Extracting navigation line for rhizome location using gradient descent and corner detection[J]. Transactions of the Chinese Society of Agricultural Engineering (Transactions of the CSAE), 2022, 38(13): 177-183. (in Chinese with English abstract)
[7] LONG Z H, XIANG Y, LEI X M, et al. Integrated indoor positioning system of greenhouse robot based on UWB/IMU/ODOM/LIDAR[J]. Sensors, 2022, 22:4819. doi: 10.3390/s22134819 LONG Z H, XIANG Y, LEI X M, et al. Integrated indoor positioning system of greenhouse robot based on UWB/IMU/ODOM/LIDAR[J]. Sensors, 2022, 22: 4819. doi: 10.3390/s22134819
[8] CAMPOS C, ELVIRA R, RODRÍGUEZ J J G, et al. ORB-SLAM3:An accurate open-source library for visual, visual-inertial and multi-map slam[J]. IEEE Transactions and Robotics, 2021, 37(6):1874-1890. doi: 10.1109/TRO.2021.3075644 CAMPOS C, ELVIRA R, RODRÍGUEZ J J G, et al. ORB-SLAM3: An accurate open-source library for visual, visual-inertial and multi-map slam[J]. IEEE Transactions and Robotics, 2021, 37(6): 1874-1890. doi: 10.1109/TRO.2021.3075644
[9] DAVISON A J, REID I D, MOLTON N D, et al. MonoSLAM:real-time single camera slam[J]. IEEE Transactions on Pattern Analysis and Machine Intelligence, 2007, 29(6):1052-1067. doi: 10.1109/TPAMI.2007.1049 DAVISON A J, REID I D, MOLTON N D, et al. MonoSLAM: real-time single camera slam[J]. IEEE Transactions on Pattern Analysis and Machine Intelligence, 2007, 29(6): 1052-1067. doi: 10.1109/TPAMI.2007.1049
[10] PIRE T, FISCHER T, CASTRO G, et al. S-PTAM:Stereo parallel tracking and mapping[J]. Robotics & Autonomous Systems, 2017, 93:27-42. PIRE T, FISCHER T, CASTRO G, et al. S-PTAM: Stereo parallel tracking and mapping[J]. Robotics & Autonomous Systems, 2017, 93: 27-42.
[11] ENGEL J, SCHÖPS T, CREMERS D. LSD-SLAM:Large-scale direct monocular SLAM[C]//13th European Conference on Computer Vision(ECCV), Zurich, Switzerland, 2014, 8690:834-849. ENGEL J, SCHÖPS T, CREMERS D. LSD-SLAM: Large-scale direct monocular SLAM[C]//13th European Conference on Computer Vision(ECCV), Zurich, Switzerland, 2014, 8690: 834-849.
[12] NEWCOMBE R A, LOVEGROVE S, DAVISON A. DTAM:Dense tracking and mapping in real time[C]//IEEE International Conference on Computer Vision (ICCV), Barcelona, Spain, 2011:2320-2327. NEWCOMBE R A, LOVEGROVE S, DAVISON A. DTAM: Dense tracking and mapping in real time[C]//IEEE International Conference on Computer Vision (ICCV), Barcelona, Spain, 2011: 2320-2327.
[13] ENGEL J, KOLTUN V, CREMERS D. Direct sparse odometry[J]. IEEE Transactions on Pattern Analysis & Machine Intelligence, 2018, 40(3):611-625. ENGEL J, KOLTUN V, CREMERS D. Direct sparse odometry[J]. IEEE Transactions on Pattern Analysis & Machine Intelligence, 2018, 40(3): 611-625.
[14] 董蕊芳,王宇鹏,阚江明. 基于改进ORB_SLAM2的机器人视觉导航方法[J]. 农业机械学报,2022,53(10):306-317. DONG Ruifang, WANG Yupeng, KAN Jiangming. Visual navigation method for robot based on improved ORB_SLAM2[J]. Transactions of the Chinese Society for Agricultural Machinery, 2022, 53(10): 306-317. (in Chinese with English abstract DONG Ruifang, WANG Yupeng, KAN Jiangming. Visual navigation method for robot based on improved ORB_SLAM2[J]. Transactions of the Chinese Society for Agricultural Machinery, 2022, 53(10): 306-317. (in Chinese with English abstract)
[15] BARTH R, HEMMING J, HENTEN E, et al. Design of an eye-in-hand sensing and servo control framework for harvesting robotics in dense vegetation[J]. Biosystems Engineering, 2016, 146:71-84. doi: 10.1016/j.biosystemseng.2015.12.001 BARTH R, HEMMING J, HENTEN E, et al. Design of an eye-in-hand sensing and servo control framework for harvesting robotics in dense vegetation[J]. Biosystems Engineering, 2016, 146: 71-84. doi: 10.1016/j.biosystemseng.2015.12.001
[16] 李晨阳,彭程,张振乾,等. 融合里程计信息的农业机器人定位与地图构建方法[J]. 农业工程学报,2021,37(21):16-23. LI Chenyang, PENG Cheng, ZHANG Zhenqian, et al. Positioning and map construction for agricultural robots integrating odometer information[J]. Transactions of the Chinese Society of Agricultural Engineering (Transactions of the CSAE), 2021, 37(21): 16-23. (in Chinese with English abstract LI Chenyang, PENG Cheng, ZHANG Zhenqian, et al. Positioning and map construction for agricultural robots integrating odometer information[J]. Transactions of the Chinese Society of Agricultural Engineering (Transactions of the CSAE), 2021, 37(21): 16-23. (in Chinese with English abstract)
[17] CHEN M Y, TANG Y C, ZOU X J, et al. 3D global mapping of large-scale unstructured orchard integrating eye-in-hand stereo vision and SLAM[J]. Computers and Electronics in Agriculture, 2021, 187:106237. CHEN M Y, TANG Y C, ZOU X J, et al. 3D global mapping of large-scale unstructured orchard integrating eye-in-hand stereo vision and SLAM[J]. Computers and Electronics in Agriculture, 2021, 187: 106237.
[18] ZHOU T H, BROWN M, SNAVELY N, et al. Unsupervised learning of depth and ego-motion from video[C]//2017 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Honolulu, HI, USA, 2017:6612-6619. ZHOU T H, BROWN M, SNAVELY N, et al. Unsupervised learning of depth and ego-motion from video[C]//2017 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Honolulu, HI, USA, 2017: 6612-6619.
[19] GODARD C, AODHA O M, FIRMAN M, et al. Digging into self-supervised monocular depth estimation[C]//2019 IEEE/CVF International Conference on Computer Vision (ICCV), Seoul, Korea, 2019:3827-3837. GODARD C, AODHA O M, FIRMAN M, et al. Digging into self-supervised monocular depth estimation[C]//2019 IEEE/CVF International Conference on Computer Vision (ICCV), Seoul, Korea, 2019: 3827-3837.
[20] YANG N, STUMBERG L V, WANG R, et al. D3 VO:Deep depth, deep pose and deep uncertainty for monocular visual odometry[C]//2020 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Seattle, WA, USA, 2020:1278-1289. YANG N, STUMBERG L V, WANG R, et al. D3 VO: Deep depth, deep pose and deep uncertainty for monocular visual odometry[C]//2020 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Seattle, WA, USA, 2020: 1278-1289.
[21] 周云成,许童羽,邓寒冰,等. 基于自监督学习的温室移动机器人位姿跟踪[J]. 农业工程学报,2021,37(9):263-274. ZHOU Yuncheng, XU Tongyu, DENG Hanbing, et al. Self-supervised pose estimation method for a mobile robot in greenhouse[J]. Transactions of the Chinese Society of Agricultural Engineering (Transactions of the CSAE), 2021, 37(9): 263-274. (in Chinese with English abstract ZHOU Yuncheng, XU Tongyu, DENG Hanbing, et al. Self-supervised pose estimation method for a mobile robot in greenhouse[J]. Transactions of the Chinese Society of Agricultural Engineering (Transactions of the CSAE), 2021, 37(9): 263-274. (in Chinese with English abstract)
[22] ZHAO W, LIU S H, SHU Y Z, et al. Towards better generalization:Joint depth-pose learning without PoseNet[C]//2020 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Seattle, WA, USA, 2020:9148-9158. ZHAO W, LIU S H, SHU Y Z, et al. Towards better generalization: Joint depth-pose learning without PoseNet[C]//2020 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Seattle, WA, USA, 2020: 9148-9158.
[23] LI S K, WU X, CAO Y D, et al. Generalizing to the open world:Deep visual odometry with online adaptation[C]//2021 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Nashville, TN, USA, 2021:13179-13188. LI S K, WU X, CAO Y D, et al. Generalizing to the open world: Deep visual odometry with online adaptation[C]// 2021 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Nashville, TN, USA, 2021: 13179-13188.
[24] LEPETIT V, MORENO-NOGUER F, FUA P. EPnP:An accurate O(n) solution to the PnP problem[J]. International Journal of Computer Vision, 2009, 81(2):155-166. doi: 10.1007/s11263-008-0152-6 LEPETIT V, MORENO-NOGUER F, FUA P. EPnP: An accurate O(n) solution to the PnP problem[J]. International Journal of Computer Vision, 2009, 81(2): 155-166. doi: 10.1007/s11263-008-0152-6
[25] MEISTER S, HUR J, ROTH S. UnFlow:Unsupervised learning of optical flow with a bidirectional census loss[C]//32nd AAAI Conference on Artificial Intelligence (AAAI-18), New Orleans, LA, USA, 2018:7251-7259. MEISTER S, HUR J, ROTH S. UnFlow: Unsupervised learning of optical flow with a bidirectional census loss[C]//32nd AAAI Conference on Artificial Intelligence (AAAI-18), New Orleans, LA, USA, 2018: 7251-7259.
[26] LIU P P, LYU M, KING I, et al. SelFlow:Self-supervised learning of optical flow[C]//2019 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Long Beach, CA, USA, 2019:4566-4575. LIU P P, LYU M, KING I, et al. SelFlow: Self-supervised learning of optical flow[C]//2019 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Long Beach, CA, USA, 2019: 4566-4575.
[27] LIU P P, KING I, LYU M R, et al. DDFlow:Learning optical flow with unlabeled data distillation[C]//33rd AAAI Conference on Artificial Intelligence (AAAI-19), Honolulu, HI, USA, 2019:8770-8777. LIU P P, KING I, LYU M R, et al. DDFlow: Learning optical flow with unlabeled data distillation[C]//33rd AAAI Conference on Artificial Intelligence (AAAI-19), Honolulu, HI, USA, 2019: 8770-8777.
[28] JONSCHKOWSKI R, STONE A, BARRON J T, et al. What matters in unsupervised optical flow[C]//16th European Conference on Computer Vision (ECCV 2020), Glasgow, UK, 2020:557-572. JONSCHKOWSKI R, STONE A, BARRON J T, et al. What matters in unsupervised optical flow[C]//16th European Conference on Computer Vision (ECCV 2020), Glasgow, UK, 2020: 557-572.
[29] LUO K M, WANG C, LIU S C, et al. UPFlow:Upsampling pyramid for unsupervised optical flow learning[C]//2021 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Nashville, TN, USA, 2021:1045-1054. LUO K M, WANG C, LIU S C, et al. UPFlow: Upsampling pyramid for unsupervised optical flow learning[C]// 2021 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Nashville, TN, USA, 2021: 1045-1054.
[30] SUNDARAM N, BROX T, KEUTZER K. Dense point trajectories by GPU-accelerated large displacement optical flow[C]//11 th European Conference on Computer Vision (ECCV 2010), Heraklion, Greece, 2010:438-451. SUNDARAM N, BROX T, KEUTZER K. Dense point trajectories by GPU-accelerated large displacement optical flow[C]//11 th European Conference on Computer Vision (ECCV 2010), Heraklion, Greece, 2010: 438-451.
[31] SUN D Q, YANG X D, LIU M Y, et al. PWC-Net:CNNs for optical flow using pyramid, warping, and cost volume[C]//2018 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Salt Lake City, UT, USA, 2018:8934-8943. SUN D Q, YANG X D, LIU M Y, et al. PWC-Net: CNNs for optical flow using pyramid, warping, and cost volume[C]// 2018 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Salt Lake City, UT, USA, 2018: 8934-8943.
[32] HARTLEY R I. In defense of the eight-point algorithm[J]. IEEE Transactions on Pattern Analysis and Machine Intelligence, 1997, 19(6):580-593. doi: 10.1109/34.601246 HARTLEY R I. In defense of the eight-point algorithm[J]. IEEE Transactions on Pattern Analysis and Machine Intelligence, 1997, 19(6): 580-593. doi: 10.1109/34.601246
[33] HINTON G, DEAN J, VINYALS O. Distilling the knowledge in a neural network[C]//28th Conference on Neural Information Processing Systems (NIPS 2014), Montreal, Canada, 2014. HINTON G, DEAN J, VINYALS O. Distilling the knowledge in a neural network[C]//28th Conference on Neural Information Processing Systems (NIPS 2014), Montreal, Canada, 2014.
[34] YU J J, HARLEY A W, De Rpanis K G. Back to basics:Unsupervised learning of optical flow via brightness constancy and motion smoothness[C]//14th European Conference on Computer Vision (ECCV 2016), Amsterdam, Netherlands, 2016:3-10. YU J J, HARLEY A W, De Rpanis K G. Back to basics: Unsupervised learning of optical flow via brightness constancy and motion smoothness[C]//14th European Conference on Computer Vision (ECCV 2016), Amsterdam, Netherlands, 2016: 3-10.
[35] PASZKE A, GROSS S, MASSA F, et al. PyTorch:An imperative style, high-performance deep learning library[C]//33rd Conference on Neural Information Processing Systems (NIPS 2019), Vancouver, Canada, 2019:8026-8037. PASZKE A, GROSS S, MASSA F, et al. PyTorch: An imperative style, high-performance deep learning library[C]//33rd Conference on Neural Information Processing Systems (NIPS 2019), Vancouver, Canada, 2019: 8026-8037.
[36] STURM J, ENGELHARD N, ENDRES F, et al. A benchmark for the evaluation of RGB-D slam systems[C]//2012 IEEE/RSJ International Conference on Intelligent Robots and Systems, Vilamoura-Algarve, Portugal, 2012:573-580. STURM J, ENGELHARD N, ENDRES F, et al. A benchmark for the evaluation of RGB-D slam systems[C]//2012 IEEE/RSJ International Conference on Intelligent Robots and Systems, Vilamoura-Algarve, Portugal, 2012: 573-580.
[37] XU H F, ZHANG J, CAI J F, et al. GMFlow:Learning optical flow via global matching[C]//2022 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), New Orleans, LA, USA, 2022:8111-8120. XU H F, ZHANG J, CAI J F, et al. GMFlow: Learning optical flow via global matching[C]//2022 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), New Orleans, LA, USA, 2022: 8111-8120.
-
期刊类型引用(6)
1. 高婧,李茂春,毛荣,张青,井立军. 1991―2022年新疆塔城地区植棉区气候变化对棉花生育期的影响. 中国棉花. 2024(02): 16-23 .  百度学术
百度学术
2. 李云霞,王国栋,刘瑜,吕宁,梁飞,范军亮,尹飞虎. 新疆典型绿洲灌区土壤理化性状与盐分离子分布特征. 农业机械学报. 2024(07): 357-364+414 . 百度学术
3. 刘雲祥,张礼,咸文荣. 青海地区花生适宜播期研究. 青海农林科技. 2024(03): 39-43 . 百度学术
4. 熊坤,马美娟,金趁意,余卫东. 播期对花生‘豫花65’生长及产量影响. 中国农学通报. 2024(32): 16-22 . 百度学术
5. 陈春波,李均力,赵炎,夏江,田伟涛,李超锋. 新疆草地时空动态及其对气候变化的响应——以昌吉回族自治州为例. 干旱区研究. 2023(09): 1484-1497 . 百度学术
6. 李欢,翟孟如,江伟,韦钢,刘苏,吕晓霞,钟昀平. 新疆冷凉区域花生高产栽培技术. 新疆农业科技. 2023(06): 24-27 . 百度学术
其他类型引用(3)

计量
- 文章访问数: 256
- HTML全文浏览量: 20
- PDF下载量: 167
- 被引次数: 9





